MongoDB is a NoSQL document store. As with other NoSQL databases there are a number of advantages to it including dynamic schema, scalability/performance and no need for ORM layer. A production deployment of MongoDb should be clustered. This will increase scalability and durability for the data. For high volume applications the number of disk operations and network transfers can overwhelm a single node. Example is any back-end for mobile apps with millions of users. On a single node memory is also a precious resource that can become scarce. Finally the whole data set can be too large to fit in one node or one set of nodes. Sharding helps to address these issues.
This post shows the setup of a sharded cluster and checking the behavior when the primary in a replicaset fails.
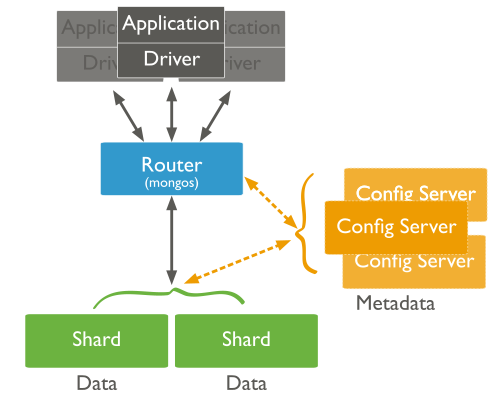
A sharded MongoDB topology looks like the following.
There are at least 3 config servers, 1 router and then the shards themselves. Each shard should ideally include at least 3 nodes/servers. One of the nodes in the shard will be elected primary and data replicates to the others in a shard. There can be many shards depending on data set size. The router routes a query to a particular shard after consulting the config servers. So on a minimum there needs to be 7 hosts for a basic sharded cluster. These have to be separate and not vms on the same machine. If these are vms on a single big server in production then we are not addressing the issues that led to the move towards sharding. However the post used vms all on ssd. The setup is described as below.
Setup details
Build 7 vms or configure separate hosts (recommended) with the following. Either an available image can be used or clone using virtualbox.
Config server
192.168.56.30
192.168.56.31
192.168.56.32
Shard's data nodes
192.168.56.40
192.168.56.41
192.168.56.42
Router
192.168.56.20
Each node runs on 64-bit Ubuntu Server 16.04 and uses MongoDB 3.4.1.
Database used is the MoT dataset from https://data.gov.uk/dataset/anonymised_mot_test
Config servers
A) Start the config servers one by one. Log into the config server and run the following command.
mongod --configsvr --replSet config_set1 --dbpath ~/mongo-data --port 27019
In the version of MongoDB used the config servers themselves are a replicaset. mongo-data is the path for storing the data files. Do this for each config server.
Log into one of the config servers in mongo and initialise them as shown:
Shard nodes
B) On each node in the shard start the mongo daemon as
mongod --shardsvr --dbpath ./mongo-data/ --replSet data_rs_1
Log into one of the data nodes and initialise them as shown
Router
C) Start the router. On the router node
mongos --configdb config_set1/192.168.56.30:27019,192.168.56.31:27019,192.168.56.32:27019
Adding shards
D) Connect to the router and add the shard to the cluster.
View the config server to confirm that the shard was added. This shows up in the SHARDING logs.
Shard the database
E) Enable sharding for the database and collection in that order. Again connect to the router to do the following.
mongo> sh.enableSharding("mot")
Then enable sharding for the collection. Also specify the key field that needs to be used for distributing the data between shards.
F) Check the shard status. On the router do a sh.status(). This should look like
Verify
G) Connect a client to the router and populate the database. After this the shard status also shows chunks of data.
H) Check the config on the cluster. Connect MongoDB Compass to the router and look into the config db.
Note that an index is created on the DB for the shard key. This is shown below.
Electing a primary on failure:
Setting the above up can be time consuming but it is all worth it as when the primary node of the shard is killed, one of the other data nodes assumes the primary position through an election. So we go and kill the primary node process. This result in heart beat failure and after waiting for a specific time frame one of the secondaries assumes primary position. This is shown below.
The primary was node 192.168.56.40.
On failure of that 192.168.56.42 is elected as primary. This shows up on the 40 node when it comes back online.
Although queries during primary election can fail it can be caught in exceptions and tired again in the application. This requires no mentioning but the daemons should be run as service.
Reference:
MongoDB docs at
https://docs.mongodb.com/manual/tutorial/deploy-shard-cluster/
This can be a bit outdated but is a good read too
https://www.digitalocean.com/community/tutorials/how-to-create-a-sharded-cluster-in-mongodb-using-an-ubuntu-12-04-vps